The aim of this document is to give developers information how to approach RESTful APIs based on HAL generally, esp. Avid’s core platform services to access assets, in this case assets of MediaCentral Asset Management service instances. – Besides general information, parts of this text were the result from solving my own misunderstandings beginning with REST, esp. HAL-based REST APIs.
It should be said that this document is meant for developers having a solid knowledge of network programming, JSON and HTTP (but not necessarily "web programming" with frameworks like JSP, ASP.NET or PHP). However, this document will also discuss some features of HTTP and the URL-standard, which are less known, but nevertheless exploited to make the HAL-based REST API work.
REST
Generally we have many means to let (local) clients communicate to (remote) services. The story evolved from inter-process communication via shared memory, over socket communication (usually via TCP/IP) with proprietary protocols, over semi-proprietary protocols (CORBA (with the extra protocol IIOP), DCOM, RPC, RMI). After that, standardized communication protocols like XML-RPC and SOAP entered the market. However, the latter technologies have been used successfully in the wild, but they put a heavy burden on administrators and developers:
-
bad compatibility
-
cumbersome, difficult and involved infrastructure
-
to a certain degree long development cycles, the productivity is heavily depending on the tool support
In simple words, to address these issues people went "back to the roots" of communication along the most common protocol stacks, until they found HTTP as the most often used common denominator. – This was effectively one of the findings in Roy Fielding’s doctoral thesis, which is nowadays applied to reinterpret and redesign client-server communication with REST.
It is important to understand that the means of communication to be found was required to be positioned on the "application layer" of protocol stacks. – This is required, because we need a protocol, which is suited to build an API on top of it, remember that API is for "Application Programming Interface"; "lower" protocols have too few semantics to be candidates to act as the basis for an API. To drive this point home, HTTP was selected as the basis for an API, replacing the other protocols. With HTTP we are standing on the shoulders of giants, because it supports many features out of the box, which we can use directly:
-
HTTP request "verbs" like GET, POST, DELETE etc., reflect (basic) operations with fixed semantics (it basically works like CRUD, but REST is not directly CRUD) ⇒ HTTP is a protocol as well as an API
-
In comparison to, e.g. SOAP or XML-RPC, in REST the URL is rather the method to be called and the method name is not somehow encoded and passed in the payload. I.e. the operation-calling infrastructure is one layer above protocols like SOAP or XML-RPC.
-
Webservers (those are "callees"), which serve HTTP are widespread, cheap or free and could even be implemented relatively easily.
-
Webclients (those are "callers"), which consume HTTP are simple to program on most platforms, because most platforms come with HTTP-support in their core libraries.
-
Basically, firing HTTP-requests as well as analyzing HTTP-traffic can be done without profound programming knowledge using the tools of the OS or free tools.
-
-
HTTP is a plain text protocol, remember that HTTP is for "Hyper Text Transport Protocol"
-
that makes programming clients even easier, because text-processing is simple
-
errors can be spotted, understood and fixed quickly
-
HTTP as Plain Text Protocol
In order to exploit HTTP for our purposes, it was required to:
-
Map API-calls to HTTP verbs, i.e. to HTTP requests the verbs are getting repurposed.
-
Define a data protocol.
-
Define how APIs and data work together and how they are linked, so it can be used as hypermedia.
In the following sections these requirements and terms will be explained. And then our approach to meet these requirements is discussed.
Potential Clients
Sending an HTTP request is even possible from the terminal/DOS box:
# Using wget: wget -qO- --header='Authorization: Bearer MAGIC' --header='Accept: application/hal+json' 'https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID' # Using curl (e.g. for macOS): curl -H 'Authorization: Bearer MAGIC' -H 'Accept: application/hal+json' 'https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID'
Dissection of the Communication with the Service
HTTP Responses use HAL
Now it’s time to talk about the response of the just sent HTTP GET request ("https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID") to retrieve the service root. What do we get then? In order to enter a REST API we have to request the entry point of that API, and this is what we just have done! The response of the service root describes the API’s entry point, or its "global functions" if you will, in a specific format (or notation). A first look at the responses body/text unleashes it as being of JSON format:
{
"_links": {
"curies": [
{
"href": "https://developer.avid.com/ctms/api/aa/linkrels/{rel}.html",
"name": "aa",
"templated": true
},
{
"href": "https://developer.avid.com/ctms/api/loc/linkrels/{rel}.html",
"name": "loc",
"templated": true
},
{
"href": "https://developer.avid.com/ctms/api/search/linkrels/{rel}.html",
"name": "search",
"templated": true
},
{
"href": "https://developer.avid.com/ctms/api/ma/linkrels/{rel}.html",
"name": "ma",
"templated": true
}
],
"self": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID"
},
"aa:assets": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets"
},
"loc:locations": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/locations"
},
"search:searches": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/searches"
},
"ma:axf-requests": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/request/axfs"
}
},
"_embedded": {
"aa:assets": {
"_links": {
"self": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets"
},
"aa:asset-by-id": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/{id}",
"templated": true
},
"aa:create-asset": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets",
"type": "application/vnd.com.avid.mam.axf+json"
},
"aa:update-asset-by-id": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/{id}",
"type": "application/vnd.com.avid.mam.axf+json",
"templated": true
},
"aa:delete-asset-by-id": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/{id}",
"templated": true
}
}
},
"loc:locations": {
"_links": {
"self": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/locations"
},
"loc:folder-by-id": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/locations/folders/{folderid}",
"templated": true
},
"loc:root-item": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/locations/folders/1"
},
"loc:root-item-templated": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/locations/folders/1{?offset,limit,sort,filter}",
"templated": true
}
}
},
"search:searches": {
"_links": {
"search:simple-search": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/searches/quick?search={search}{&offset,limit}",
"templated": true
},
"search:advanced-search": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/searches/advanced{?offset,limit}",
"templated": true
}
}
}
}
}To be frank, the response’s body looks "involved", the content of the JSON data portion is structured in a complex way. What we see here is data, expressed via another JSON-based protocol, which is put into the HTTP responses body. This protocol is called Hypertext Application Language (HAL). To drive this point home: communication with the Upstream is done via HTTP and HAL. HTTP "drives" operations and transports data, HAL represents the data and concretizes the API. So, HAL is used for the communication with the Connectivity Toolkit for the Media Services, in other words it is used for accessing MediaCentral Production Management, Newsroom Management and Asset Management via the Upstream services. The (very dense) HAL specification can be found here: http://stateless.co/hal_specification.html and the more elaborate HAL RFC draft can be found here: https://tools.ietf.org/adoc/draft-kelly-json-hal-06. The author of HAL, Mike Kelly, says this:
HAL is a little bit like adoc for machines, in that it is generic and designed to drive many different types of application via hyperlinks. The difference is that adoc has features for helping 'human actors' move through a web application to achieve their goals, whereas HAL is intended for helping 'automated actors' move through a web API to achieve their goals.
HAL is one implementation of the HATEOAS (Hypertext As The Engine Of Application State) aspect of the REST paradigm. In this model, operations that are relevant for a given resource are abstracted into link relations, which are a way of identifying URLs that can be used to execute those operations. Link relations form the hypertext network that create a resource space to be navigated. The abstract nature of the link relations isolates server changes from the client code. In HAL, the link relation names are durable, so it’s possible to change the associated URL without necessarily modifying the client. This will be explained further below, and additional information can be found at http://stateless.co/hal_specification.html. In a sense the idea behind HAL is to have a protocol, which defines a standardized way to make JSON a hypertext format, this is done by formalizing links in HAL.
|
Note
|
In most cases, when making requests against CTMS' services, we have to make sure to set the "Accept" HTTP header field to the value "application/hal+json" (this header field was set in all the examples used in this text)! This way the client tells the service that it can deal with "HAL" content in JSON format. - Services can reject requests, w/o the Accept header field value "application/hal+json" with the response "406 - Not Acceptable". There are some exceptions to this rule, where services can respond with other representations. |
To see how HAL works in the context of these APIs, we’re going to analyze the previous response.
Links
HAL-formatted objects can have properties, link relations and embedded resources. The service root resource has no data itself, it is just the main entry point to get to other resources, called sub resources from the perspective of the primary resource (service root in this case), via the link relations, therefore it has no properties.
On the first level there is a single field named "_links"; as its name suggests, it just contains links. Within "_links", we have basically two sorts of information: (1) the property "curies", containing another array of links, and (2) a couple of (bare JSON) properties, representing links each. We’ll talk about "curies" in a minute, also notice that there is another special link "self", which links to the resource of the GET request, we have just requested reflectively, i.e. the URL of the service root! Maybe you doubt the use of this link, but that each resource has a self link is an important feature, when working with embedded resources.
The other links, namely "aa:assets","loc:locations","search:searches" and "ma:axf-requests" link to other resources, which allow access to further groups of functionality.
Link Relations and CURIEs
The names of the properties of the other links are following a specific syntax: a prefix (e.g. "aa") followed by a suffix (e.g. "assets") separated with a colon resulting in "aa:assets". - Properties identifying link objects are called "link relations", or short "link rels", i.e. "aa:assets" is a link rel. . Another metaphor for link rels are "method names" or "method selectors", on which different HTTP verbs can be used and on which bodies of different Content-Type (sticking to the metaphor: the method arguments) could be used, we’ll discuss this later. The prefixes of the link rels are directly connected to the names of the CURIEs, listed in the property "curies", CURIE is for "compact URI expression". - What is the idea behind CURIEs?
{
"_links": {
"curies": [
{
"href": "https://developer.avid.com/ctms/api/aa/linkrels/{rel}.html",
"name": "aa",
"templated": true
}
],
"aa:assets": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets"
}
}
}Let’s inspect the CURIE "aa". The CURIE’s name "aa" acts as prefix for all link rels of a common subject if you will. Each CURIE is associated to a URI, specified in the CURIE’s href property, e.g. for "aa" we have "https://developer.avid.com/ctms/api/aa/linkrels/{rel}.html". The CURIE "aa" is also "templated", "templated" means, that we could fill the placeholder "{rel}" in the CURIE’s URI with a link rel’s suffix and get an expanded URL, e.g. for the link rel "aa:assets", we would get the expanded URL "https://developer.avid.com/ctms/api/aa/linkrels/assets.html". - The idea behind those expanded URLs is to put an optional documentation of the link rel behind that URL, but in practice, this URL does not have an obligatory meaning, it should however be unique. In practice, and this is also a matter of lengthly discussions concerning HAL, a link rel should never change, i.e. the link rels "aa:assets" and another link rel "bb:assets" are considered different, even if their CURIEs' URIs are equivalent! - That means, that a CURIE does not directly specify a namespace identified by its URI, but it defines a prefix to give link rels a kind of structure. Just keep in mind that CURIE URIs have no meaning at all, maybe they specify/name the vendor and refer to a documentation, but not more. There is no mechanism like XML-namespacing involved!
Rules for link rels:
-
Link rels should apply CURIEs. Either one of the predefined ones (please see below), or new, maybe vendor-specific ones.
-
Only use hyphens in link rels and CURIE URIs to enhance readability, don’t use underscores, only use lower case letters.
-
For the time being, link rels are evaluated in a case insensitive manner.
Predefined names of the CURIEs:
-
aa (https://developer.avid.com/ctms/api/aa/linkrels/{rel}.html) ⇒ common media asset (Avid’s core services dealing with assets)
-
loc (https://developer.avid.com/ctms/api/loc/linkrels/{rel}.html) ⇒ locations management ("foldermanagement")
-
search (https://developer.avid.com/ctms/api/search/linkrels/{rel}.html) ⇒ support for search abilities
-
pa (https://developer.avid.com/ctms/api/pa/linkrels/{rel}.html) ⇒ MediaCentral Production Management media asset
-
ia (https://developer.avid.com/ctms/api/ia/linkrels/{rel}.html) ⇒ MediaCentral Newsroom Management media asset
-
ma (https://developer.avid.com/ctms/api/ma/linkrels/{rel}.html) ⇒ MediaCentral Asset Management media asset
I have a very simple rule for app developers: Ignore the presence of CURIEs mentally! They have no substantial meaning at all.
Link Objects
For the time being we only discussed the link rels to uniquely designate links. But what do those link rels virtually designate? The JSON-object right from the colon of a link rel property string under the "_links" property is called a link object. (The link rel "curies" does even have an array of link objects associated with it, as explained above, we could list the CURIEs for "aa", "pa" etc. in the "curies" array.) So, we have this general structure of links, link rels and link objects:

Let’s inspect the link object of the link rel "aa:assets":
{
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets"
}Now let us just follow the link rel’s "aa:assets" href "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets".
wget -qO- --header='Authorization: Bearer MAGIC' --header='Accept: application/hal+json' 'https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets'We’ll get this response:
{
"_links": {
"curies": [
{
"href": "https://developer.avid.com/ctms/api/aa/linkrels/{rel}.html",
"name": "aa",
"templated": true
}
],
"self": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets"
},
"aa:asset-by-id": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/{id}",
"templated": true
},
"aa:create-asset": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets",
"type": "application/vnd.com.avid.mam.axf+json"
},
"aa:update-asset-by-id": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/{id}",
"type": "application/vnd.com.avid.mam.axf+json",
"templated": true
},
"aa:delete-asset-by-id": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/{id}",
"templated": true
}
}
}What do we see here:
-
The link rel "self" does exactly refer to the href "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets", we followed to get this response.
-
There are a number of other link rels, which have operation-like names "aa:create-asset" and "aa:delete-asset-by-id".
-
Mind, that some of those link objects are templated, i.e. their property "templated" is set to true and in the values of the href properties we have URI strings, which contain sections marked with placeholders written in curly braces, e.g. "{id}". - A "follower" of these links is meant to fill these placeholders in order to get a "full" URL string, which can then be used in an HTTP request. (Notice, that the placeholders need not to be written as last component of a URI.) We’ll discuss about the meaning of templated URIs and how the placeholders are filled in more detail some sections below, but the basics will get clear as we continue the discussion.
Resources
What is in the Resource?
Let’s continue using the HAL response we got from requesting "aa:assets". - The whole HAL-based JSON object is a so-called "resource" in HAL lingo. So, the very first request we did to get the service root, responded with the service root resource! Then we started from this resource, following the links to get other resources. The term resource is actually a REST term, and the returned HAL-based JSON object is in reality a "representation of an underlying resource", but HAL uses the term "resource" interchangeably with "representation of the resource".
The aa:assets resource is a collection, meaning that it represents all of the assets in the associated system. The link relations in this resource correspond to operations that apply effectively to the whole asset data store, including creating, retrieving and deleting individual assets.
Link Rels and Resources: A link rel is a key to a certain link object. A link object contains an href with a URL, that acts as a pointer to a certain resource. Abbreviated: link rels point to resources.
Using the REST-based API means following the links given in a resource at hand. In the case of the resource "aa:assets" we’ll select the link rel "aa:asset-by-id". We want to follow the href in "aa:asset-by-id"'s link object, therefore we have to:
-
expand the URI template given in the href property to get a fully blown URL by replacing the placeholders by meaningful values
-
fire a HTTP GET request with the expanded URL to get the resource "behind" that URL
All right, in order to expand the URI template in the href, i.e. "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/{id}", we have to know something about the semantics of the link, and what the link, i.e. the HTTP request, will return. In this case, yes I know that from the APIs documentation, I have to replace "{id}" by the id of the asset I want to retrieve. Assuming, that the id is "12374176-1c8d-42b3-9d10-7cf19b0f3fb2", the constructed expanded URL would be "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2". Having that completed URL, we can issue another HTTP GET request, to retrieve the resource of that asset. To have that request work, we have to pass the access token again in the header field "Authorization". E.g. via wget from the command line:
wget -qO- --header='Authorization: Bearer MAGIC' --header='Accept: application/hal+json' 'https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2'The HTTP response of that GET request carries another resource in its body: the asset resource. Let’s inspect it!
{
"base": {
"id": "12374176-1c8d-42b3-9d10-7cf19b0f3fb2",
"type": "asset.VIDEO",
"systemType": "interplay-mam",
"systemID": "SYSTEMID"
},
"common": {
"name": "Demo - Updated Asset as of 04-06-16 12:42:58 014_A",
"creator": "admin",
"created": "2016-01-28T12:21:18+01:00",
"modifier": "Service-mamctc",
"modified": "2016-04-06T12:42:58+02:00",
"startTC": "00:00:00.000"
},
"_links": {
"curies": [
{
"href": "https://developer.avid.com/ctms/api/aa/linkrels/{rel}.html",
"name": "aa",
"templated": true
},
{
"href": "https://developer.avid.com/ctms/api/ma/linkrels/{rel}.html",
"name": "ma",
"templated": true
}
],
"self": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2"
},
"aa:update-asset": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2;type=asset.VIDEO",
"type": "application/vnd.com.avid.mam.axf+json"
},
"ma:asset-axf": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2;type=asset.VIDEO/axf"
},
"aa:attributes": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2;type=asset.VIDEO/attributes"
},
"ma:asset-attributes-axf": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2;type=asset.VIDEO/attributes/axf"
},
"aa:time-based": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2;type=asset.VIDEO/time-based"
},
"ma:asset-strata": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2;type=asset.VIDEO/strata"
},
"ma:asset-strata-axf": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2;type=asset.VIDEO/strata/axf"
},
"aa:delete-asset": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2"
},
"aa:access-by-type-usage-and-protocol": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2;type=asset.VIDEO/access{?filetype,usage,protocol}",
"templated": true
},
"ma:essence-packages": {
"href": "http:/update:8080/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2;type=asset.VIDEO/essencepackages"
},
"profile": {
"href": "http://meta.avid.com/profiles/mam/asset"
}
}
}Reconsidering the structure of the response of calling "aa:assets", we’ll notice that this response also is a resource! - Of course it is, because HAL-based APIs only use resources as substantial means of communication. The structure of the "aa:assets" resource and the structure of the "aa:asset" resource only have the "_links" property and esp. the "curies" and "self" properties thereof in common (the hrefs of both "self" link objects do of course differ, because they are different resources). To drive this point home: JSON objects, representing HAL resources can contain links (property "_links") as well as a bunch of arbitrary other properties on the "top level". - In this case the "aa:asset"-resources properties denote more meta information about the individual asset we’ve queried. The properties of a resource are case-sensitive following JSON/JavaScript rules, the casing of the properties might be camelcase or hyphenation (Lisp-case).
We followed the link rel "aa:asset-by-id" to get this resource. In HAL, the original link rel that leads to this resource is implicitly also the type of the resource if you will. In the case of "aa:asset-by-id", this would mean that the resource in the response is an "aa:asset-by-id"-resource, but for matters of clarity, we consider this being an "aa:asset"-resource actually. - As we already discussed, the self link refers to the URL, which was expanded from the original link rels URI template. So the original URL or self link is basically the location of that specific resource.
However, we should discuss the link rels in the property "_links" we have in this resource:
-
All link objects, except those in "curies" and "ma:essence-packages" are not templated.
-
The "untemplated" link objects do influence the asset represented by the "aa:asset"-resource itself. I.e. if we follow the link rel "aa:attributes", we’ll get the "aa:attributes" of this ("self") "aa:asset"-resource and if we use "aa:delete-asset", however, this ("self") "aa:asset"-resource will be deleted.
Properties of a Resource
Like every HAL resource we have the property "_links", which we have just discussed, esp. the link rels and link objects. But this time we have more "top-level" properties in that resource (compared to the "aa:assets" resource).
base
The property base refers to another JSON object, that contains a quadruple of common information about the asset, which is represented by this resource. The base property is mandatory for asset objects! I will not go into detail here, the quadruple is just the information, which is needed to have the "Common Object API" working with this data.
common
The additional property common contains other metadata (e.g. "name", "created" (date)).
Other Properties
A resource can also have more specific properties apart from base, common and _links, which will not be discussed here.
Using the API
HATEOAS
What we have done now is basically using the data of one resource as hypermedia to access another resource, i.e. from the "aa:assets" to a specific "aa:asset". The term hypermedia comes into play here, because we have used URIs specified in hrefs, which were provided by the server with a previous (HTTP) response. The way in which we provided the links was HAL, i.e. the "_links" property, therefore HAL is a hypertext format. This principle of using a REST API is called Hypermedia as the Engine of Application State (HATEOAS). HATEOAS used by a REST client is similar to a human being exploring the web with a web browser following links. The idea is that there is no completely fixed API, but using the correct calls or following the correct links is a matter of discovery via semantics. - It is like a webserver delivering a website to the client’s web browser and the client can select among the links of that website. Another important point is that we can continue applying HATEOAS with the "aa:asset"-resource, esp. with its links, without prior knowledge of the "initial" URL. → It doesn’t matter from where those links came initially, we can continue working with them. (Well, in our case we have to remember and pass the access token as well, which might break the clean idea of HATEOAS somewhat.)
|
Note
|
Advanced information: It should be said that HATEOAS could also be implemented via HTTP "Link" header fields instead of hypertext as payload. E.g. for forward- and backward navigation there exists RCF 5988 for the link structure. |
What is the benefit for a client to use HATEOAS?
The idea is to keep business logic away from the client, only the presence of links controls what the client can actually request. Sure, it adds more "protocol complexity" to the client, because it must find links and interact with them. But the client is freed from "business complexity", e.g. there is no need to check details like "if in that field there is a particular value, then I’m allowed to do a specific operation". If such detailed logic would be literally hard coded on the client side, it would be impossible to change it on the server side. In the following text it is explained how we supply this powerful concept to the client.
What we did
So far so good, but another problem is emerging. We understand that a REST API can be used by "guessing" like a person surfing the web does after the idea of HATEOAS, but how much semantic knowledge is required to use the API? I.e. when we have a link in our hands, what does it really do, which request payload has to be provided and which payload will be present in the response? Well, HTTP provides another means to handle this: verbs (also known as request methods). The HTTP verbs we have used up to now are GET requests. GET requests have the semantics of querying data, or "requesting HTTP content". E.g. this request will fetch the resource specified in the request (here the asset of id "12374176-1c8d-42b3-9d10-7cf19b0f3fb2"):
GET https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2 HTTP/1.1
Now let’s assume, we want to create a certain resource (e.g. another asset). Following the idea of HATEOAS together with HTTP verbs, we would have to issue an HTTP POST request against the resource in question, incl. an acceptable payload in the body:
POST https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/ HTTP/1.1
{...body...}
Will that POST work and do the expected thing, i.e. create a new asset? We decided to use link rels named in an understandable way plus hrefs having the operation in their name combined with HTTP verbs to handle the operations. Argumentation: However, using, or, rather "guessing" only the HTTP verbs to discover functionalities has some serious downsides. We still need to know the allowed HTTP verbs on a resource. To be frank, HTTP provides the OPTIONS verb (to be issued against a specific resource) to give us exactly this information, but we still have no semantic information. I.e. it might be useful to get information about the "createablity" of a resource (then OPTIONS will return the POST verb as one of the allowed verbs), but the knowledge about the bare availability of POST and other verbs doesn’t tell us anything about the payload we have to send. In other words: the supported media type of the content is not known to us. Even worse, the media type of the content of the same resource could vary for different HTTP verbs. - Meaning we could have one format for PUT and another format for PATCH. Therefore the combination of was used.
Instead of only using different HTTP verbs to represent different operations on the same resource, we explicitly define different link rels representing different operations (this approach was taken from the Amazon REST/HAL API). - Then the API-user can directly see which operations are supported on a resource in the HAL’s "_links" property.
Instead of "guessing", how assets can be created with an HTTP verb, we just name that operation in a clear way in our API. Remember, that we got this response following the link rel "aa:assets":
{
"_links": {
"curies": [
{
"href": "https://developer.avid.com/ctms/api/aa/linkrels/{rel}.html",
"name": "aa",
"templated": true
}
],
"self": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets"
},
"aa:create-asset": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets",
"type": "application/vnd.com.avid.mam.axf+json"
},
...
}
}With that information we can call the link rel "aa:create-asset", it is fully clear what it does. Fair enough, it is still required, that the caller knows that a POST requests needs to be issued, the combination of the properly named link rel "aa:create-asset" and using it with the POST verb will create the new asset:
POST https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/ HTTP/1.1
{...body...}
Another example: deleting assets. In the resource "aa:assets" we’re going to find the link rel "aa:delete-asset-by-id". - Once again, it is completely clear what it does:
{
"_links": {
"curies": [
{
"href": "https://developer.avid.com/ctms/api/aa/linkrels/{rel}.html",
"name": "aa",
"templated": true
}
],
"self": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets"
},
"aa:delete-asset-by-id": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/{id}",
"templated": true
},
...
}
}and finally we use "aa:delete-asset-by-id"'s resolved href like so (once again, the caller needs to know something about the HTTP verb to use, which is DELETE in this case):
DELETE https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2 HTTP/1.1
So, in the end, the platform API does not make use of "clean" HATEOAS if you will. It does not solely count on the callers' knowledge of the semantics of certain HTTP verbs, instead it provides links having meaningful link rels, which allow proper navigation in the API. Instead of mere HATEOAS, we defined some rules for discovery (link rel names, URI templates etc.), so that callers can make educated guesses, how the API works.
|
Note
|
Please notice that we could also GET the resource "aa:asset" and use the link rel "aa:delete-asset" to delete it!
|
Caching of URLs
From the standpoint of purity, clients should never apply/rely on hard coded ("bookmarked") URLs and they should never build URLs manually, but instead follow link rels every time, e.g. from the root resource to the elementary resource in question. Sure, this puts a greater burden on clients, but this is basically the way hypermedia should work. However, in order to have more efficiency a caching strategy might be appropriate.:
When it comes to retrieving the entry point of a service, is that something that I as a consumer of that and possibly other services should it be cached or would I retrieve the entry point every time I need to interact with the service again? If caching is ok, what is a good granularity of expiring that information?
-
cache per the duration of the current service request (when I am a service myself and currently running in the context of an exposed service method)
-
cache per the life time of the service itself
-
cache per a certain expiration time
-
invalidate the cache when expiration time is due or an exception was detected
Embedded Resources
We just mentioned the concept of embedded resources, which is also a genuine concept of HAL. Therefore some of the links, e.g. "aa:asset-by-id", do also support specifying child resources, which should be embedded in the returned resource. - As already discussed, links, which allow specification of embedded resources are not marked in a special way, instead some known semantics/prior knowledge (hopefully documented) is required.
The idea of embedding is of course interesting to save us from many web requests and getting stuff in bulk instead. Mind that the size of messages are limited on the bus! Let’s Inspect a resource containing an embedded resource by requesting this:
GET http:/upstream:8080/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2?embed=asset-attributes-axf
The returned response looks like this (some parts have been elided for brevity):
{
"base": { ... },
"common": { ... },
"_links": {
"curies": [
{
"href": "https://developer.avid.com/ctms/api/ma/linkrels/{rel}.html",
"name": "ma",
"templated": true
},
...
],
"self": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2"
},
...
},
"_embedded": {
"ma:asset-attributes-axf": {
"axf": {
"objects": [
{
"assetId": "12374176-1c8d-42b3-9d10-7cf19b0f3fb2",
"class": "VIDEO",
"attributes": [
{
"name": "MAINTITLE",
"value": "Demo - Updated Asset as of 03-18-16 10:04:05 968_A"
},
{
"name": "MODIFICATION_DATETIME",
"value": "20160318102954"
},
...
]
}
]
},
"_links": {
"self": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/12374176-1c8d-42b3-9d10-7cf19b0f3fb2;type=asset.VIDEO/attributes/axf"
},
...
}
}
}
}Let’s dissect this HAL resource from the JSON’s root. We have the top-level properties "base", "common" and "_links" as always, also mind that "_links" contains the link rel "curies" among others.
The new property is named "_embedded", as the reader may have noticed, those properties with the "_"-prefix have a predefined meaning in HAL. Within "_embedded" we find the embedded resource as response to the issued request. It is not required to explain the details here, because the structure of the resource is basically equivalent to the stuff we have already discussed, and it also depends on semantics, which have to be documented somewhere. However, there is one important point: curies will only be defined in the very top-level resource, e.g. for the embedded resource object of "type" "ma:asset-attributes-axf" the CURIE "ma" is defined on the top-level resource. - It means that for link rel discovery, it is required to analyze the top-level resource for CURIEs, not the embedded one.
Mind, that embedded resources do also have self links, this is required because we have to be able to associate hrefs to those resources, because we don’t know their origin based on the original request-URL of the "surrounding" resource.
For completeness, it should be mentioned that the JSON-object right from the colon of a link rel property string under the "_embedded" property is called resource object. So, we have this general structure of embedded resources, link rels and resource objects:
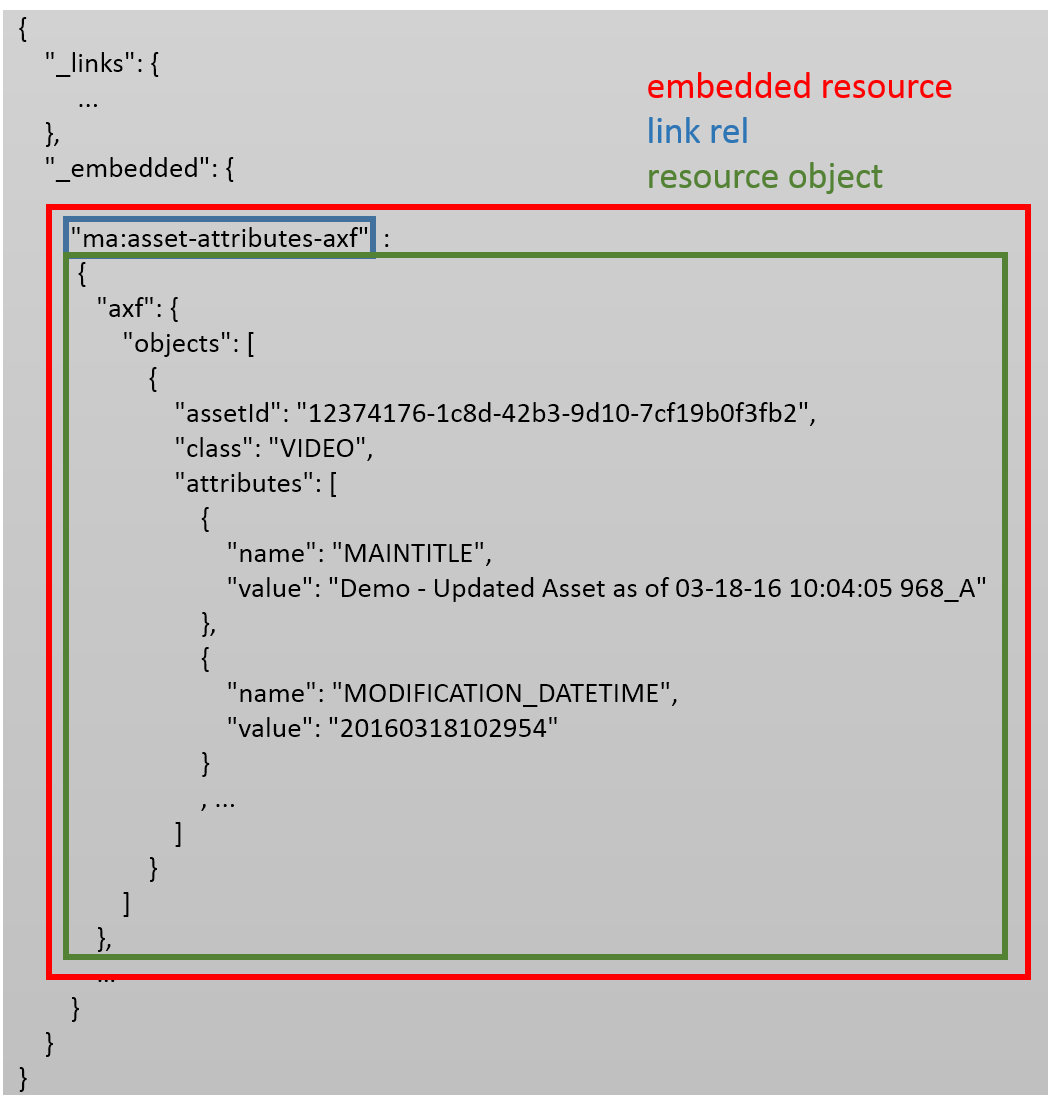
Automatically embedded Resources
Esp. requesting the service root resource, "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/", does always embed the resources "aa:assets", "loc:locations" and "search:searches":
{
"_links": {
"curies": [
{
"href": "https://developer.avid.com/ctms/api/aa/linkrels/{rel}.html",
"name": "aa",
"templated": true
},
{
"href": "https://developer.avid.com/ctms/api/loc/linkrels/{rel}.html",
"name": "loc",
"templated": true
},
{
"href": "https://developer.avid.com/ctms/api/search/linkrels/{rel}.html",
"name": "search",
"templated": true
},
{
"href": "https://developer.avid.com/ctms/api/ma/linkrels/{rel}.html",
"name": "ma",
"templated": true
}
],
"self": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID"
},
...
},
"_embedded": {
"aa:assets": {
"_links": {
"self": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets"
},
"aa:asset-by-id": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/assets/{id}",
"templated": true
},
...
}
},
"loc:locations": {
"_links": {
"self": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/locations"
},
"loc:folder-by-id": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/locations/folders/{id}",
"templated": true
},
...
}
},
"search:searches": {
"_links": {
"search:simple-search": {
"href": "https://upstream/apis/avid.mam.assets.access;version=0;realm=SYSTEMID/searches/quick?search={search}{&offset,limit}",
"templated": true
},
...
}
}
}
}In other words, one could either follow the link rel "aa:assets" from the service root in order to get further links for, e.g. the link rel "aa:asset-by-id", or one could directly follow the link rel "aa:asset-by-id" on the embedded "aa:assets" resource. As can be seen the CURIEs for the embedded resources are all defined on the very top level resource, as shown in the example having "ma:asset-attributes-axf" embedded before.
Optional and Requestable Properties
When dealing with HAL resources, you occasionally stumble over a dilemma: On the one hand, a HAL resource should be complete in the sense that it contains all information that is useful for a client. On the other hand, some pieces of information are probably not supported by all systems or are very expensive to get.
To deal with that, some properties in this documentation are marked as optional. This means:
-
A service can return the property but doesn’t have to.
-
A client must not rely on the existence of the property.
Of course, that puts the burden on the client. It must implement logic to deal with optional properties. To simplify that we declare some properties as optional, but requestable in this documentation. Optional, but requestable properties can be requested with the query parameter insist. This means:
-
A service can return the property but doesn’t have to.
-
If the client requests a property xyz using the query parameter insist=xyz then the service MUST return it.
-
A client that relies on a property xyz MUST request it using insist=xyz when calling a service.
This is typically used for properties that are expensive to get. An example is the property totalNumber when returning a defined range out of a large list of items, e.g. when returning one page of the results of a search, or when returning one page of items in a folder. For a client, the total number is useful to show a UI control for paging. But it can be very expensive to get the total number of items. It can, for example, require additional database queries. So, the performance would suffer if the property is returned all the time, even though a lot of clients won’t need that number at all.
Dealing with Content
!!Notice that HAL-based JSON can not be converted into XML directly. The problem is that HAL uses JSON-properties having colons in their names like "aa:attributes". - Such a property name can not be used as name for an XML element or attribute, because colon is used as a separator for namespace-qualified names in XML!!
Accept Types in Requests
Mind, that the Accept header field value "application/hal+json" must be specified generally!
Content Types in Requests
There are three request verbs accepting a body, which are relevant to us: POST, PATCH and PUT. The verbs PATCH (e.g. link rel "aa:update-asset"), POST (e.g. with link rel "aa:assets") and PUT (e.g. with link rel "aa:asset-by-id") accept content of type "application/vnd.com.avid.mam.axf+json". This vendor-specific content type represents a JSON-variant of the AXF XML-structures in MediaCentral Asset Management. Btw. the link rel "aa:asset-by-id" is an example of how the same link rel can be used as a method name to issue a GET (get the asset as HAL response) request as well as a PUT (set an asset’s axf) request.
Content Types and other Header Fields in Responses
Up to now we only discussed HAL as content type of the responses of our requests. And this is also the basic implication: the Content-Type of a response for the platform is HAL by default. This fact can be inspected by reading the header fields of an HTTP response, the default Content-Type header field of a platform response has the value "application/hal+json". All responses of the platform need to have the Content-Type header field specified!
In case of errors, the Content-Type will have the value "application/vnd.avid.problem+json".
The header field "Location" is the substantial data in the response of requesting "aa:create-asset", i.e. the body of the response of "aa:create-asset" is not of interest. Location contains the URL referring to the just created asset, if creation went well.
Content Types in Requests
There are three request verbs accepting a body, which are relevant to us: POST, PATCH and PUT. The verbs PATCH (e.g. link rel "aa:update-asset"), POST (e.g. with link rel "aa:assets") and PUT (e.g. with link rel "aa:asset-by-id") accept content of type "application/vnd.com.avid.mam.axf+json". This vendor-specific content type represents a JSON-variant of MediaCentral Asset Management’s AXF XML-structures. Btw. the link rel "aa:asset-by-id" is an example of how the same link rel can be used as a method name to issue a GET (get the asset as HAL response) request as well as a PUT (set an asset’s axf) request.
Restrictions on HTTP Header Fields
-
User defined header fields are not allowed! So, neither the caller nor the callee have to struggle with those.
-
Header field names have to be considered case-insensitive by the standard/RFC. - Upstream converts header field names to lower-case automatically.
Restrictions on HTTP Body Content
-
If POST requests have to be issued, all arguments have to be specified in the body, query parameters should not be used in that case.
-
Upstream supports XML starting with version 5.1.0.
Errors
Up to now, the basic communication protocol we use for the REST-based connectivity toolkit is HTTP and we kind of "re-purposed" HTTP verbs as well as resources to act as means to transport our API calls and data. The same is true for error cases. Our REST-based API also makes use of HTTP error codes to signal error cases to the caller. The Content-Type of an error-response can have the value "application/vnd.avid.problem+json" to signal that it is an SDK-related error, rather than other "infrastructure" issue. - When the Content-Type is "application/vnd.avid.problem+json", a description/message of the error is awaited in the response body. This text will not go into all the gory details of existing HTTP error codes, and how those should be applied in a clean REST interface. Instead the general idea will be shown. The details about error codes, which may be issued by API calls, are documented in the API documentation in detailed manner.
It should be said that callers of REST APIs should always be aware of the mentioned "infrastructure" issue, which has nothing to do with the requested service per se. Especially timeouts or unreachable endpoints could happen at any time during the application of REST and HATEOAS.
|
Note
|
Advanced information: After understanding the most important HTTP idioms, it is time to discuss another way to implement asynchronous communication between client and server. Some sections above, we discussed how a client can establish communication with the server in an asynchronous manner in order to have more responsiveness. Sometimes, there is the need to have time consuming operations on the server side, which could lead to timeouts on the client side. (Mind that esp. in case of the platform, synchronized execution on the server side could lead to bus timeouts.) Also initiating asynchronous calls from the client won’t help in this case, because it would only put the waiting-for-result-code into another thread, and then the timeout would just happen in that thread. To handle such situations there also exists an asynchronous "HTTP-communication-pattern" using certain HTTP status codes. It works like so:
This pattern provides a solution to deal with time consuming operations on the server to avoid timeouts. The burden on this pattern is clear: it needs to be implemented on the server explicitly. |